2023-06-10 08:41 发布
发布

作者 | 邓咏仪
编辑 | 苏建勋
36氪获悉,6月7日,虎博科技正式发布并开源其自研大模型TigerBot。同时,虎博科技还发布了大模型应用开发所需的全套API,以及多领域专业数据。
虎博科技成立于2017年,是一家专注于深度学习及NLP(自然语言处理)技术的AI公司,36氪曾多次报道。此前,经过多年技术探索和积累,虎博科技已经拥有包括智能搜索、智能推荐、机器阅读理解、总结、翻译、舆情分析及撰稿在内的关键技术,亦有全球各行业的专业信息数据积累。
2022年11月,OpenAI发布ChatGPT,掀起了全球的AI大模型科技浪潮,中国市场也出现了不少团队自研AI大模型的尝试,虎博科技也是其中之一。
本次虎博科技所发布的自研大模型TigerBot,是一个多语言多任务大规模语言模型,经历3个月的封闭式开发和超过3000次实验迭代,当前已经迭代出第一个MVP版本。
从功能上,Tigerbot已经包含大部分生成和理解类的能力,具体包括几大部分:
内容生成:辅助用户解决创作类问题,快速生成营销文案、评论、新闻稿等等。另外,Tigetbot也支持图片生成——模型可以实现文生图,进行插图创作等

图片生成
开放问答:用户向Tigerbot提出问题,比如烹饪攻略、长文本总结、文本理解、角色对话、润色等等

开放式问答
提取信息:比如有目的地获取关键信息、提取数字、主要内容等等

长文本解读
在3个月封闭开发背后,是一支精干的团队。虎博科技创始人兼CEO陈烨对36氪表示,在大模型研发上,虎博团队致敬了硅谷经典的“车库创业”模式,团队开始只有5个人,CEO同时担任首席程序员及首席AI科学家。
“在大模型的研发上,我们坚信顶尖团队能起到的作用,团队规模不必太大,但技术需要过硬。在我们从0到1的研发过程中,我们核心的研发团队一直保持在4-5个人,以及密切合作的研发状态。”陈烨表示。
从模型效果上看,虎博Tigerbot根据OpenAI InstructGPT论文的公开 NLP数据集上进行评测,TigerBot-7B对应OpenAI同等规模的6B版本,其综合表现能够达到OpenAI效果的96%。
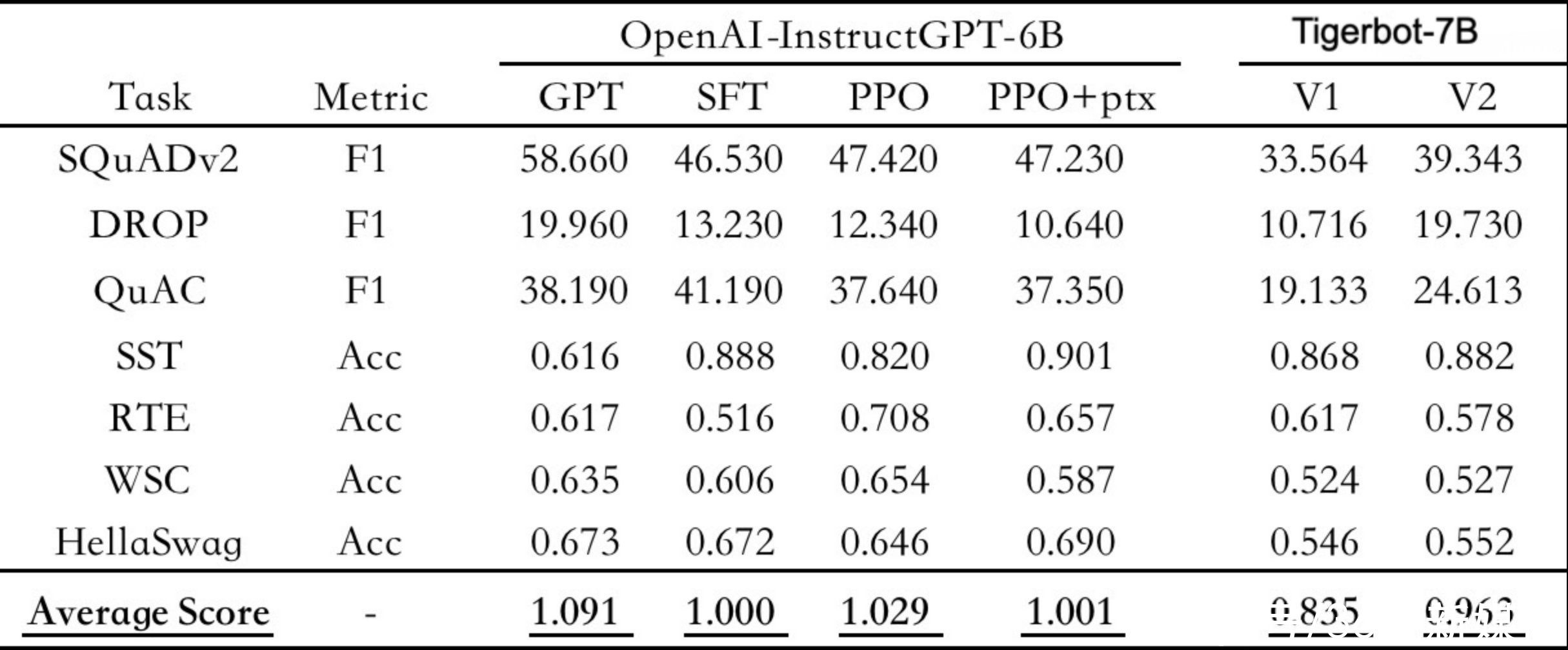
以OpenAI-instruct GPT-6B-SFT为基准,归一化并平均各模型的得分情况 来源:虎博科技
在过去三个月中,虎博科技主要基于GPT和BLOOM两个开源模型基础上,在模型架构和算法侧做了一系列优化。陈烨对36氪表示,虎博科技在技术突破上,主要集中在原创的监督和微调方法上。“从整个技术角度来说,监督微调的方法是大模型这件事的核心,能够影响模型效果的七到八成。”
比如,大模型浪潮来临后,困扰业界的一个难题在于大模型的“幻觉”——即大模型输出的结果,和人类说的话一样自然,但在事实层面会“胡说八道”。
陈烨以实际案例举例,针对这一问题,虎博应用了一些经典的监督学习方法,如Ensemble和Probabilistic Modeling,结合到大模型中。
“假设人类在问模型一个事实性问题,Tigerbot不会只是简单地生成自然语言,而是同步利用更少量的数据就能知道人类意图——在回答上,则会更好的权衡事实性和创造性。”陈烨补充。这样的结果是,机器在训练模型中算力和数据的消耗,会比同等档次模型要小。
针对中文语境,虎博科技从分词器(Tokenizer)到训练算法等方面做了针对性算法优化,使得模型更懂中文指令,提高了问答结果的中国文化属性。(注:这里调后了一段,因为在模型里,事实性和创造性决定了它是不是会胡说八道,中文环境的针对性算法优化,可以让它更懂中国人的交流,类似于几个同学在一起,总有1个比其他人文学底蕴更好一点)
而在并⾏训练上,虎博的大模型团队也突破了比如 deep-speed 等主流框架中若⼲内存和通信问题,使得在千卡环境下,可实现训练数⽉⽆间断。
虎博科技在大模型研发上选择走开源路线。此次开源内容包含模型、代码、数据三部分,包含TigerBot-7B-sft、 TigerBot-7B-base、TigerBot-180B-research等多个模型版本;基本训练且覆盖双卡推理 180B 模型的量化和推理代码;以及达100G的预训练数据、监督微调1G/100万条数据。
目前,这些内容已经全部在Github中发布(链接见此)。之所以选择开源路线,陈烨表示,推进人类文明的技术变革往往源于本能、直觉和偶然性,拥有自由的创新精神是根本。
“大模型技术就像是一门新兴学科,是颠覆式且长周期的,未来的可能性超越PC和互联网。现阶段过早和过于理性地探讨产品、应用、场景和商业化或许没有必要,更重要的是推广这一人工智能基础设施的原创突破,促进技术的发展和更新。”
出于上述的考虑,虎博除了一部分积累的预训练数据集,也同时开源了系统性的中文数据搜集和清洗方法论。陈烨并不认为数据会成为壁垒:“更重要的是团队对于数据清洗的理论和系统性的高度,这是一个长期的系统工程。”
虎博科技自成立之初就专注在中文NLP的技术和产品研发上,积累了大量高质量的中文预训练数据,本次发布的100G预训练数据,就是其中的一部分。未来,虎博还将开放大量的金融、法律、百科等领域专业数据,供应用开发者使用。
此前几年,虎博科技基于NLP,开发了主要面向泛金融领域的NLP产品,如舆情监测、搜索、知识图谱等,也已经用api的方式服务B端客户。本次大模型的发布也会与虎博的业务相结合——当前,虎博科技已经面向老客户提供包括内容生成类的功能模块。陈烨表示,大模型技术浪潮来临后,在市场侧感觉“客户决策速度比以前更快,产品落地速度也更快。”
未来,虎博科技将持续投入力量到大模型的研发和落地中。陈烨谈及了正在研发或者正在完善的一些功能,如研究助手TigerDoc、文创和营销工具等,虎博科技也正在内测部分面向个人的类助手产品。
欢迎交流
欢迎关注
本文内容来自用户上传并发布或网络新闻客户端自媒体,本站点仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请联系删除。


 首页
首页